Table of Contents
Introduction: Computer Vision AI as the Invisible Foundation of Autonomy
Autonomy collapses when machines go blind. A self-driving car that cannot parse the street becomes a hazard. A drone that loses sight of obstacles plummets. A robotic arm that misreads depth crushes what it should grasp. These failures expose a truth that often hides beneath algorithmic complexity: Computer Vision AI is not one feature among many but the foundation that makes autonomous action possible at all.
Computer Vision AI transforms light into understanding. It converts photons bouncing off surfaces into structured information that machines can process and act upon. Without this translation layer, autonomous systems drift in a void of uninterpreted data. They hold processing power but lack the sensory grounding that connects computation to consequence. The difference between an intelligent machine and a runaway calculator lies in this capacity to see, interpret, and respond to the physical world.
This article unpacks six essential layers that Computer Vision AI provides to autonomous systems. Each layer builds upon the last, creating a stack of capabilities that transforms raw pixels into reliable action. These layers are perception, spatial understanding, contextual interpretation, decision triggering, feedback integration, and environmental scaling. Together, they form the backbone of autonomy across industries and applications.
Computer Vision AI Compared to Other AI Components
| AI Component | Primary Function |
|---|---|
| Computer Vision AI | Translates visual data into actionable machine understanding of physical environments |
| Machine Learning | Identifies patterns in data and improves predictions through experience |
| Natural Language Processing | Processes and generates human language for communication and comprehension |
| Intelligent Robotics | Integrates sensors, actuators, and control systems for physical interaction |
| Reinforcement Learning | Optimizes decisions through trial, error, and reward-based feedback loops |
| Expert Systems | Applies codified domain knowledge through rule-based logical inference |
| Planning & Optimization | Determines optimal sequences of actions to achieve defined objectives |
| Knowledge Representation | Structures information in formats that enable reasoning and retrieval |
1. Computer Vision AI as the Perception Layer That Grounds AI in Reality
Perception anchors everything else. Computer Vision AI converts the chaos of raw visual input into stable signals that machines can process reliably. A camera captures millions of pixels per frame. That data means nothing until Computer Vision AI extracts edges, shapes, textures, and patterns that correspond to objects, surfaces, and boundaries in physical space.
This grounding function separates functional autonomy from blind automation. A warehouse robot navigating aisles relies on Computer Vision AI to distinguish floor from shelf, pallet from wall, human from machine. These distinctions seem obvious to biological vision but require extensive processing for artificial intelligence and automation systems. The perception layer must handle variations in lighting, shadows, reflections, and occlusions that change constantly across real environments.
Roads illustrate this challenge clearly. Autonomous vehicles encounter faded lane markings, unexpected debris, construction zones, and weather conditions that obscure visibility. Computer Vision AI must maintain stable perception through all these variations. When perception fails, the entire autonomous stack collapses because higher reasoning functions receive corrupted or incomplete data. Decision-making algorithms cannot compensate for perception errors because they operate on whatever signals the vision layer provides.
Factory floors add another dimension. Industrial robots use Computer Vision AI to identify parts, verify assembly steps, and detect defects. The perception layer must function under harsh lighting, handle reflective metal surfaces, and process objects moving at high speeds. Failures at this layer propagate immediately into production errors, safety incidents, or system shutdowns.
Drone flight paths demonstrate perception under motion. Computer Vision AI on aerial vehicles must process visual information while the platform moves, tilts, and changes altitude. The perception layer stabilizes this input, extracts relevant environmental features, and maintains spatial reference despite constant perspective shifts. Without reliable perception, autonomous flight becomes impossible because the system cannot distinguish safe paths from obstacles.
Computer Vision AI Perception Layer Functions
| Perception Function | Role in Autonomous Systems |
|---|---|
| Edge and Shape Detection | Identifies object boundaries and structural forms in visual data |
| Texture Analysis | Differentiates surfaces and materials for navigation and manipulation |
| Pattern Recognition | Extracts recurring visual features across changing conditions |
| Occlusion Handling | Maintains object understanding when visibility is partially blocked |
| Lighting Normalization | Preserves perception accuracy across varied illumination environments |
| Motion Stabilization | Processes visual data consistently despite camera or subject movement |
2. Computer Vision AI and Spatial Understanding as a Layer of Environmental Awareness
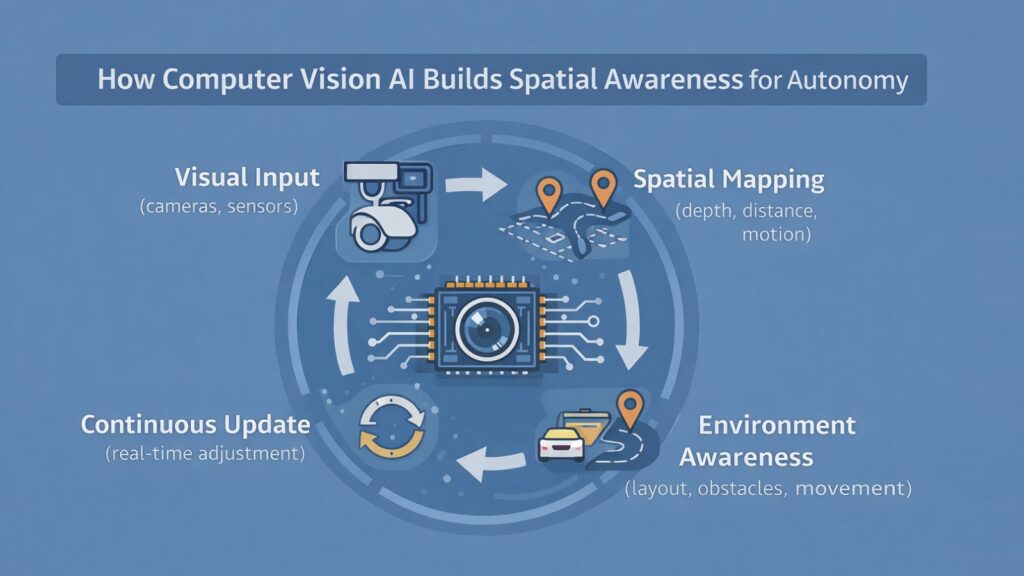
Spatial intelligence transforms flat images into a three-dimensional understanding. Computer Vision AI does not simply identify what exists but determines where things are, how far away they sit, and how they move through space. Autonomy depends on this continuous spatial reasoning because machines must navigate, manipulate, and interact with the physical world.
Depth perception forms the foundation of spatial understanding. Stereo vision systems use multiple camera feeds to triangulate distance. LIDAR integration combines laser ranging with visual data to build precise spatial maps. Monocular systems infer depth from visual cues like relative size, occlusion patterns, and motion parallax. Computer Vision AI synthesizes these inputs into coherent spatial models that update in real time.
Distance calculations matter immensely for collision avoidance. An autonomous vehicle approaching an intersection must judge the distance to crossing traffic, pedestrians, and static obstacles simultaneously. Computer Vision AI processes these spatial relationships frame by frame, tracking velocities and predicting trajectories. Small errors in distance estimation translate directly into safety failures because braking distances and turning radii depend on accurate spatial data.
Motion tracking adds a temporal dimension to spatial awareness. Computer Vision AI must distinguish stationary objects from moving ones, estimate velocities, and predict future positions. A robot working alongside humans needs to know not just where people are but where they will be in the next second. This predictive spatial understanding enables safe interaction in shared environments.
Spatial relationships between objects enable manipulation tasks. A robotic gripper approaching a bin of parts uses Computer Vision AI to understand not just individual item locations but how objects stack, overlap, and support each other. The vision system must compute grasp points, approach angles, and clearance paths through cluttered three-dimensional space.
Failures in spatial reasoning cause immediate behavioral breakdowns. A delivery robot that misjudges doorway width becomes stuck. A surgical robot that miscalculates tool depth causes injury. An agricultural drone that misreads crop height crashes into vegetation. These failures trace back to spatial understanding errors in the Computer Vision AI layer.
Computer Vision AI Spatial Understanding Capabilities
| Spatial Capability | Application in Autonomy |
|---|---|
| Depth Estimation | Calculates distance to objects for navigation and collision prevention |
| 3D Reconstruction | Builds volumetric models of environments from visual input |
| Object Localization | Determines precise positions of entities within reference frames |
| Trajectory Prediction | Forecasts future positions based on observed motion patterns |
| Clearance Calculation | Assesses available space for movement and manipulation |
| Relative Positioning | Maps spatial relationships between multiple objects simultaneously |
3. Computer Vision AI as the Context Layer That Interprets Situations, Not Images
Recognition differs fundamentally from understanding. Computer Vision AI must move beyond labeling pixels to interpreting what visual information means in context. A pedestrian standing on a sidewalk presents different implications than the same person stepping off a curb. The pixels change minimally, but the situational meaning shifts entirely.
Contextual interpretation relies on pattern recognition across time and space. Computer Vision AI analyzes sequences of frames rather than isolated images. A person raising their arm might signal a turn, hail a taxi, or wave hello. The vision system must consider the surrounding context, such as location, traffic patterns, and other visible cues to interpret intent correctly.
Abnormal pattern detection depends on contextual understanding. Security systems use Computer Vision AI to identify suspicious behavior, which requires knowing what normal looks like in specific environments. Loitering means something different at a bus stop than in a restricted area. The vision layer must calibrate expectations based on location, time, and typical activity patterns.
Risk assessment emerges from contextual interpretation. Computer Vision AI in autonomous vehicles must recognize scenarios that indicate elevated danger even when no explicit threat appears. A ball rolling into the street suggests a child might follow. A car door opening into traffic signals a potential collision. These contextual cues trigger precautionary responses before direct threats materialize.
Industrial applications demand contextual precision. Computer Vision AI monitoring assembly lines must distinguish acceptable variation from defects that indicate systemic problems. A minor scratch might be cosmetic or structural, depending on location and depth. The vision system interprets context to classify findings appropriately.
Autonomy fails when systems see correctly but misunderstand the meaning. A robot that identifies all objects in a room but misreads their functional relationships cannot complete tasks effectively. Computer Vision AI must provide not just inventory but understanding of how elements interact, which objects enable which actions, and what configurations indicate problems versus normal states.
Computer Vision AI Contextual Interpretation Mechanisms
| Contextual Mechanism | Function in Situational Awareness |
|---|---|
| Temporal Sequence Analysis | Interprets meaning by tracking changes across consecutive frames |
| Intent Recognition | Infers probable future actions from visible behavioral cues |
| Anomaly Detection | Identifies patterns that deviate from established environmental norms |
| Scene Understanding | Comprehends relationships between objects within complex environments |
| Risk Signal Identification | Recognizes visual indicators of potential hazards or failures |
| Functional Relationship Mapping | Determines how visible elements interact and enable actions |
4. Computer Vision AI as the Decision-Triggering Layer in Autonomous Systems
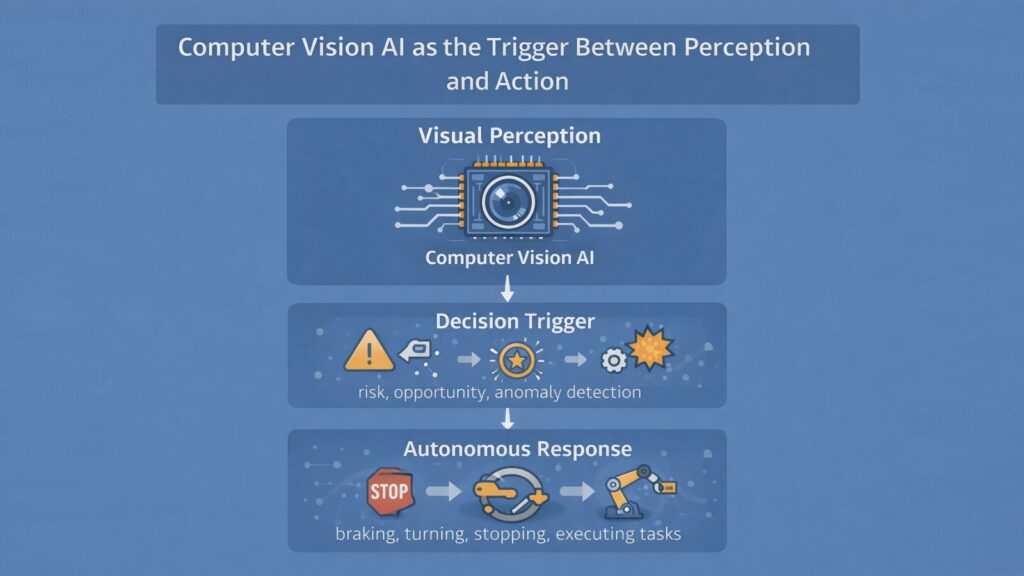
Visual signals initiate action. Computer Vision AI feeds directly into decision-making engines that control brakes, motors, actuators, and other effectors. The vision layer does not merely inform decisions but triggers them through structured output that decision algorithms can process immediately.
Timing matters critically in autonomous systems. Computer Vision AI must deliver usable signals within milliseconds of visual events. A pedestrian stepping into a vehicle’s path requires immediate braking. The vision system must detect the event, classify the threat level, and send triggering signals to safety systems faster than a human driver could react. Delays measured in fractions of a second determine whether autonomous systems prevent accidents or cause them.
Confidence levels shape decision quality. Computer Vision AI attaches certainty estimates to its outputs. A vision system might be 95 percent confident that an object is a pedestrian and 60 percent confident that it is moving toward the vehicle. Decision engines use these confidence levels to select appropriate responses. High-confidence threats trigger immediate defensive action, while ambiguous signals might prompt additional sensor validation or cautious slowdown.
Uncertainty handling distinguishes robust autonomy from brittle automation. Computer Vision AI encounters situations where visual data remains genuinely ambiguous despite processing. Fog, snow, or unusual lighting can prevent reliable classification. The vision layer must communicate this uncertainty explicitly rather than guessing. Decision systems can then invoke fallback behaviors like reduced speed or human handoff.
Navigation changes flow directly from visual triggers. Computer Vision AI, detecting a blocked path triggers replanning algorithms. Recognizing a parking space initiates docking maneuvers. Identifying a charging station activates approach protocols. Each visual detection serves as a discrete trigger that launches specific behavioral sequences.
Task execution in manipulation systems depends on visual confirmation. A robotic arm uses Computer Vision AI to verify that a part is properly positioned before executing a grasp. Visual feedback triggers each step of complex assembly sequences. The perception-decision-action chain operates continuously, with vision providing the sensory triggers that advance autonomous processes.
Computer Vision AI Decision Triggering Elements
| Triggering Element | Role in Autonomous Decision Making |
|---|---|
| Event Detection Latency | Determines response speed from visual stimulus to system action |
| Classification Confidence | Provides certainty estimates that guide decision algorithm selection |
| Threat Level Assessment | Quantifies urgency to prioritize among competing action triggers |
| Ambiguity Signaling | Communicates perception uncertainty to enable appropriate fallbacks |
| State Change Detection | Identifies transitions that require behavioral adjustments |
| Confirmation Gating | Validates preconditions before initiating irreversible actions |
5. Computer Vision AI as the Feedback Layer That Enables Self-Correction
Vision closes the loop between action and outcome. Computer Vision AI allows autonomous systems to observe the results of their own decisions and adjust accordingly. This feedback function transforms one-shot automation into adaptive intelligence that improves through operation.
Feedback operates continuously rather than episodically. After a robotic gripper executes a grasp, Computer Vision AI verifies whether the object is secure. If the grip fails, the vision system detects the error and triggers corrective action. This visual confirmation happens dozens of times per second in fast manipulation tasks, creating a tight feedback loop that enables precise control.
Error detection through vision enables real-time correction. An autonomous vehicle that drifts slightly from the lane center uses Computer Vision AI to detect the deviation and trigger steering adjustments. The vision layer provides constant feedback about the actual position relative to the intended path. This continuous error signal drives corrective actions that maintain stable navigation.
Behavioral adjustment emerges from accumulated visual feedback. Computer Vision AI tracking the outcomes of past actions enables learning systems to refine their decision parameters. A warehouse robot that frequently misjudges shelf clearance can adjust its spatial safety margins based on visual evidence of near-misses or collisions. The vision layer provides the ground truth that calibrates future behavior.
Quality control loops depend entirely on visual feedback. Manufacturing systems use Computer Vision AI to inspect finished products and detect defects. This inspection feedback triggers rework, adjustment of upstream parameters, or alerting of maintenance needs. The vision layer transforms production from open-loop fabrication to closed-loop quality management.
Predictive maintenance uses visual feedback to anticipate failures. Computer Vision AI monitoring equipment observes wear patterns, alignment drift, or debris accumulation. These visual indicators predict mechanical failures before they occur. The feedback function extends beyond immediate task execution to system health monitoring.
Self-improvement in autonomous systems requires visual confirmation of outcomes. Reinforcement learning algorithms depend on feedback about whether actions achieved intended results. Computer Vision AI provides this outcome assessment by observing environmental changes that result from system actions. The vision layer enables machines to learn from experience rather than merely executing programmed routines.
Computer Vision AI Feedback Integration Functions
| Feedback Function | Application in Self-Correction |
|---|---|
| Outcome Verification | Confirms whether executed actions achieved intended results |
| Deviation Detection | Identifies discrepancies between expected and actual states |
| Performance Tracking | Monitors task execution quality across operations |
| Wear Pattern Analysis | Observes gradual changes that indicate degradation or drift |
| Success Rate Measurement | Quantifies achievement rates to guide parameter adjustment |
| Real-Time Correction Signaling | Provides immediate error signals for dynamic adjustment |
6. Computer Vision AI as the Scaling Layer That Makes Autonomy Reliable Everywhere
Autonomy must function across endless variation. Computer Vision AI that works in controlled laboratory settings often fails when deployed in diverse real-world environments. The scaling layer addresses robustness across lighting conditions, geographies, cultural contexts, and unpredictable scenarios that laboratory testing cannot anticipate.
Lighting presents enormous challenges to visual systems. Computer Vision AI must process scenes in bright sunlight, deep shadow, night conditions, fog, rain, and every gradation between. Cameras designed for one lighting range saturate or lose detail in others. The vision layer must adapt dynamically, adjusting exposure, gain, and processing parameters to maintain reliable perception across 24-hour operation.
Geographic variation affects visual environments profoundly. Road markings, signage, vehicle types, and infrastructure differ between regions. Computer Vision AI trained primarily on American highways may struggle with European roundabouts or Asian megacities. The scaling layer requires exposure to diverse training data and adaptive algorithms that generalize beyond initial training contexts.
Cultural differences manifest visually. Pedestrian behavior, clothing styles, gesture meanings, and urban design vary across cultures. Computer Vision AI must interpret these variations correctly to avoid dangerous misunderstandings. A gesture that signals stopping in one culture might mean proceeding in another. The vision layer needs cultural context awareness to operate globally.
Environmental extremes test system limits. Desert sand, arctic ice, tropical vegetation, and urban canyons each present distinct visual challenges. Computer Vision AI must maintain functionality despite dust, moisture, extreme temperatures, and unusual visual textures that fall outside typical operating parameters. Robustness requires extensive validation across environmental extremes.
Edge cases concentrate risk in autonomous systems. Computer Vision AI performs well on common scenarios but often fails on rare events that training data underrepresents. A child in a Halloween costume, a mattress in a highway, or unusual weather phenomena can confuse vision systems. The scaling layer must handle long-tail distributions of visual events that occur infrequently but matter enormously.
Real-world deployment reveals scaling failures that benchmarks miss. Benchmark accuracy measures performance on curated datasets under controlled conditions. Actual autonomy operates continuously across years and millions of encounters. Computer Vision AI must achieve reliability rates orders of magnitude higher than laboratory demonstrations suggest. The gap between 95 percent accuracy and 99.9999 percent reliability determines whether autonomous systems remain experimental curiosities or become dependable infrastructure.
Computer Vision AI Environmental Scaling Challenges
| Scaling Challenge | Impact on Autonomous Reliability |
|---|---|
| Illumination Variability | Requires adaptation across extreme lighting from darkness to glare |
| Geographic Diversity | Demands generalization to infrastructure and visual norms worldwide |
| Weather Resilience | Must maintain function through rain, snow, fog, and dust |
| Cultural Context Adaptation | Needs interpretation frameworks for region-specific visual patterns |
| Edge Case Handling | Requires robust responses to rare but critical visual scenarios |
| Long-Term Reliability | Must sustain accuracy across millions of operational hours |
Conclusion: Computer Vision AI as the Backbone That Holds Autonomous Intelligence Together
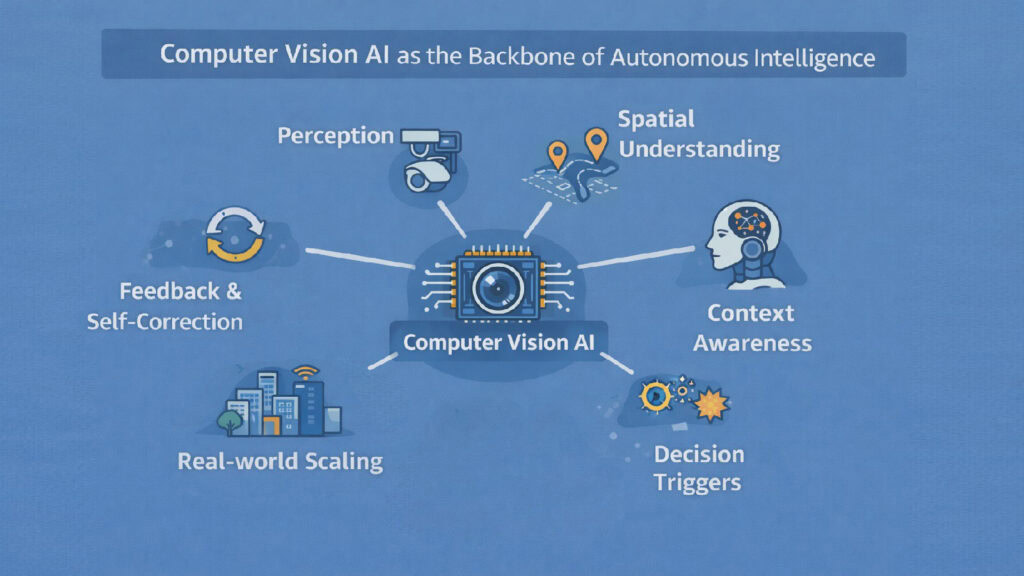
These six layers form an integrated system rather than separate capabilities. Computer Vision AI grounds autonomous systems in physical reality through perception. It provides spatial awareness that enables navigation and manipulation. It interprets context so machines understand situations rather than merely cataloging objects. It triggers decisions at the precise moments when visual information demands action. It closes feedback loops that allow self-correction and continuous improvement. It scales across the environmental diversity that real-world deployment requires.
Computer Vision AI emerges not as one algorithm or technique but as a stacked infrastructure that transforms light into intelligent action. The perception layer converts photons to data structures. The spatial layer adds geometric understanding. The context layer provides meaning. The decision layer triggers action. The feedback layer enables learning. The scaling layer ensures reliability. Together, they create the sensory foundation that autonomous intelligence cannot exist without.
Future autonomous systems will depend even more heavily on robust Computer Vision AI. As machines operate in increasingly complex and unstructured environments, visual understanding becomes the limiting factor for autonomous capability. The path forward requires viewing Computer Vision AI as essential infrastructure rather than an optional enhancement. Every autonomous system needs eyes that see reliably, understand accurately, and adapt continuously.
Computer Vision AI is indispensable to autonomous intelligence. It is not one capability among many but the sensory backbone that connects digital processing to physical reality. Without reliable vision, autonomy remains confined to structured environments and predictable scenarios. With it, machines can navigate the messy complexity of the real world. The difference between automation and autonomy lies in these six essential layers that transform sight into understanding and understanding into action.
Computer Vision AI Layers in Autonomous System Architecture
| System Layer | Contribution to Autonomous Intelligence |
|---|---|
| Perception Foundation | Converts raw visual input into stable machine-readable representations |
| Spatial Awareness | Provides geometric understanding of environments in three dimensions |
| Contextual Interpretation | Enables situational understanding beyond object recognition |
| Decision Integration | Triggers appropriate actions based on visual state assessment |
| Feedback Mechanism | Allows observation of action outcomes for continuous correction |
| Environmental Scaling | Ensures reliable operation across diverse real-world conditions |
Read More Tech Articles
- Quantum Computer Anatomy: 8 Powerful Components Inside
- Artificial Intelligence: 8 Powerful Insights You Must Know
- Quantum Computing: 6 Powerful Concepts Driving Innovation
- 8 Powerful Smart Devices To Brighten Your Life
- 8 E-Readers: Epic Characters in a Library Adventure
- Smart TV Brands: 8 Epic Directors for Screen Magic
- Tablet Brands as Superheroes: 8 Amazing Tech Avengers
- Discover 8 Smart Speaker Brands As Motivational Speakers
- Laptop Brands as Celebrities: Meet 8 Alluring Stars
- Reimagine 10 Best Smartphone Brands As Real Personalities


