
Table of Contents
Introduction: Natural Language Processing and the Illusion of Reading
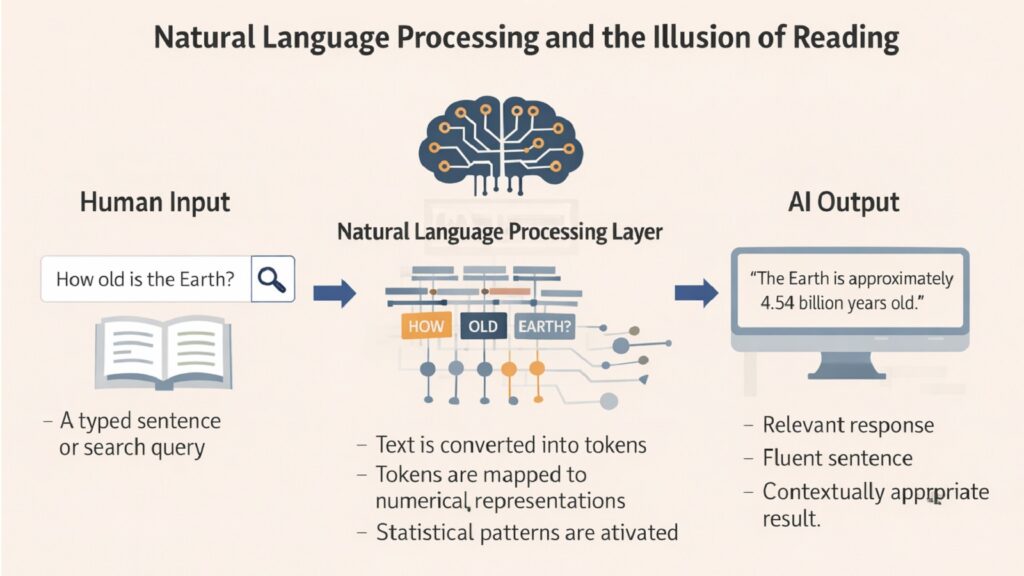
When you type a question into a search engine and receive a precise answer within milliseconds, something remarkable happens. The system appears to read your words, understand your intent, and respond with clarity. But this appearance masks a strange truth. The machine never reads the way you do. It processes symbols through mathematical relationships while creating an impression so convincing that most users never question what lies beneath.
Natural Language Processing (aka NLP) represents a branch of artificial intelligence that enables machines to work with human language. Unlike human reading, which involves comprehension and meaning-making, Natural Language Processing operates through pattern recognition and statistical probability. When you ask your phone a question or receive an email suggestion, you witness the output of systems that respond to language without experiencing it. They detect structures, predict continuations, and generate coherent responses using mechanisms entirely different from understanding.
The effectiveness of Natural Language Processing emerges from six distinct technical mechanisms. These mechanisms allow machines to parse text, identify patterns, calculate probabilities, track context, learn from exposure, and simulate understanding. Each method contributes to the larger illusion that machines comprehend language. Together, they form a system powerful enough to translate documents, answer questions, and even generate original text that feels remarkably human.
This article reveals how Natural Language Processing achieves functional reading without true comprehension. The six mechanisms described here explain why AI can respond to language so effectively while remaining fundamentally different from human minds. Understanding these processes helps clarify both the capabilities and the boundaries of modern language technology.
Natural Language Processing Compared to Other AI Sub-Systems
| AI Sub-System | Primary Function and Relationship to NLP |
|---|---|
| Natural Language Processing | Processes human language through tokenization, pattern recognition, and probability calculations to enable text understanding and generation without semantic comprehension |
| Machine Learning | Provides the foundational algorithms that Natural Language Processing systems use to identify patterns and improve performance through training on large datasets |
| Computer Vision | Analyzes visual information through pixel processing and object recognition, operating parallel to Natural Language Processing but focusing on images rather than text |
| Robotics | Integrates multiple AI systems including Natural Language Processing for voice commands while focusing on physical movement and manipulation in real environments |
| Reinforcement Learning | Trains systems through reward signals and trial-and-error, often combined with Natural Language Processing for dialogue optimization and conversational improvement |
| Expert Systems | Uses rule-based logic and predefined knowledge structures, contrasting with Natural Language Processing’s statistical approach to handling language ambiguity |
| Planning and Optimization | Solves sequential decision problems and resource allocation tasks, occasionally incorporating Natural Language Processing for instruction interpretation |
| Knowledge Representation | Structures information in formal ontologies and semantic networks, providing frameworks that Natural Language Processing can query but cannot inherently create |
1. Natural Language Processing and the Breakdown of Language Into Symbols
Before any machine can work with language, it must transform words into something it can manipulate. Natural Language Processing begins by breaking text into tokens, which are discrete units that represent words, parts of words, or even individual characters. This process, called tokenization, converts flowing sentences into arrays of symbols that bear no resemblance to human reading. Where you see a sentence as a connected thought, the system sees a sequence of numerical identifiers.
The transformation happens instantly and invisibly. A sentence like “The cat sat on the mat” becomes a series of codes that correspond to each word. More sophisticated systems break words into subword units, allowing them to handle unfamiliar terms by recognizing familiar components. This approach enables Natural Language Processing to work with new words it has never encountered by assembling meaning from smaller pieces it has seen before.
Once language becomes tokenized, every subsequent operation occurs in this symbolic space. The machine never returns to the original words as meaningful units. It calculates relationships between tokens, measures distances in multidimensional space, and applies mathematical transformations. This fundamental conversion represents the first step in reading without comprehension. Natural Language Processing cannot function without it because machines require numerical representations to perform calculations.
The efficiency of tokenization determines how well Natural Language Processing can handle complex language. Poor tokenization creates ambiguity and reduces accuracy. Effective tokenization preserves important distinctions while maintaining computational efficiency. Modern systems use sophisticated methods that balance these competing demands, creating token vocabularies that capture language diversity without becoming unwieldy.
This preliminary analysis establishes the foundation for all subsequent developments. Without converting language into processable symbols, Natural Language Processing cannot begin its work. The illusion of reading starts here, at the moment when meaningful words become meaningless numbers that machines can manipulate.
NLP Tokenization Methods and Characteristics
| Tokenization Approach | Key Features and Applications in NLP |
|---|---|
| Word-Level Tokenization | Treats each complete word as a single token, creating large vocabularies but struggling with rare words and requiring extensive memory for Natural Language Processing models |
| Character-Level Tokenization | Breaks text into individual letters, producing small vocabularies but losing word-level meaning and requiring Natural Language Processing systems to learn language from scratch |
| Subword Tokenization | Divides words into meaningful fragments using algorithms like Byte Pair Encoding, balancing vocabulary size with flexibility for Natural Language Processing applications |
| Byte-Level Processing | Operates on raw bytes rather than characters, enabling Natural Language Processing to handle any language or symbol system without predefined character sets |
| Sentence Piece Tokenization | Treats text as raw input without assuming word boundaries, particularly useful for Natural Language Processing in languages without clear spacing like Japanese or Chinese |
| Morphological Tokenization | Segments words based on linguistic structure like prefixes and suffixes, helping Natural Language Processing capture grammatical relationships and word formation patterns |
2. Natural Language Processing and Pattern Recognition Over Word Meaning
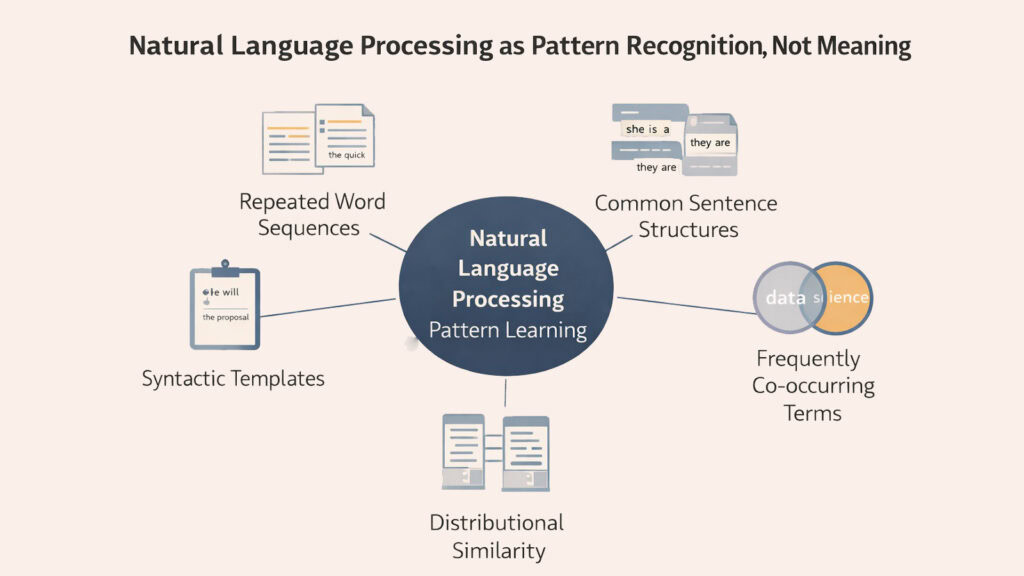
Once language exists as tokens, Natural Language Processing begins detecting patterns across millions of examples. The system never learns what words mean in any human sense. Instead, it recognizes which tokens tend to appear together and which sequences occur frequently across diverse texts. This pattern recognition forms the backbone of how machines process language without understanding it.
Consider how often the word “strong” appears near “coffee” compared to how often it appears near “weak.” Natural Language Processing systems track these co-occurrences across vast text collections, building statistical maps of language use. When the system encounters “strong” in a new context, it activates associations with words that have appeared nearby in its training data. This process has nothing to do with knowing that coffee can have a bold flavor. It simply reflects observed patterns.
The power of pattern recognition becomes apparent when Natural Language Processing handles complex sentences. Systems identify subject-verb-object structures not by understanding grammar but by recognizing recurring arrangements. They learn that certain word types tend to occupy certain positions relative to other word types. This statistical knowledge allows them to parse sentences accurately without possessing any explicit grammatical rules.
Human readers interpret language through meaning and context, drawing on life experience and cultural knowledge. Natural Language Processing relies entirely on distributional patterns. It cannot know what anything truly signifies, but it can predict with remarkable accuracy what should come next based on what came before. This distinction explains both the capabilities and the fundamental limitations of language technology.
The effectiveness of pattern recognition grows with the size and diversity of training data. More examples mean more patterns, which translates to better performance across varied contexts. Modern Natural Language Processing systems train on billions of sentences, allowing them to recognize subtle patterns that smaller systems would miss. This scale compensates somewhat for the absence of genuine understanding.
NLP Pattern Recognition Mechanisms
| Pattern Type | How NLP Detects and Uses Language Patterns |
|---|---|
| Co-occurrence Patterns | Tracks which words appear together frequently across texts, enabling Natural Language Processing to predict likely word combinations without understanding semantic relationships |
| Positional Patterns | Identifies where specific word types tend to appear in sentences, allowing Natural Language Processing to parse grammatical structure through statistical position rather than rules |
| Sequence Patterns | Recognizes common phrase structures and sentence templates that recur across diverse texts, helping Natural Language Processing generate fluent output by following observed conventions |
| Dependency Patterns | Maps relationships between words based on their typical connections in training data, enabling Natural Language Processing to understand syntax through statistical association |
| Discourse Patterns | Detects how sentences typically connect across paragraphs and documents, allowing Natural Language Processing to maintain coherence over longer texts through pattern replication |
| Domain Patterns | Learns specialized language patterns specific to fields like medicine or law, enabling Natural Language Processing to adapt its predictions to context-specific vocabulary and phrasing |
3. Natural Language Processing and Probability as a Reading Strategy
Every time Natural Language Processing generates or interprets text, it makes probabilistic calculations. The system examines what has appeared so far and computes which token should come next based on likelihood. This probability-driven approach replaces interpretation with prediction. The machine does not decide what makes sense semantically. It selects what the data suggests is most probable.
Imagine reading a sentence that begins “The sun rises in the…” Your mind immediately anticipates “east” because you understand astronomy and geography. Natural Language Processing arrives at the same prediction through entirely different means. It has processed millions of sentences where “rises in the” precedes “east” far more often than any alternative. The calculation involves no knowledge of celestial mechanics, only statistical frequency.
This probabilistic framework extends beyond simple word prediction. When Natural Language Processing translates languages, it calculates the most likely target language sequence given the source text. When it answers questions, it generates responses by selecting high-probability continuations that maintain coherence with the query. Every output represents the path of highest probability through an enormous space of possible text.
The sophistication of modern Natural Language Processing lies in how it calculates these probabilities. Simple systems might only consider the immediately preceding word. Advanced models incorporate information from hundreds or thousands of earlier tokens, weighing complex interactions to determine likelihood. This expanded context window allows for more nuanced predictions while maintaining the same fundamental approach.
Probability-based reading explains why Natural Language Processing sometimes produces confident but incorrect outputs. The system generates what the data suggests is most likely, not what is necessarily true or accurate. When training data contains biases or errors, those patterns influence probability calculations. Natural Language Processing has no mechanism for stepping back and questioning whether its high-probability prediction actually makes sense in reality.
NLP Probability Applications
| Probability Function | Role in NLP Text Generation and Analysis |
|---|---|
| Next Token Prediction | Calculates likelihood of each possible next word, forming the foundation of how Natural Language Processing generates coherent text one token at a time |
| Conditional Probability | Evaluates likelihood of word sequences given previous context, enabling Natural Language Processing to maintain grammatical and thematic consistency across sentences |
| Language Model Scoring | Assigns probability scores to complete sentences, allowing Natural Language Processing to rank alternative interpretations or translations by statistical plausibility |
| Attention Weighting | Distributes probability mass across input tokens, helping Natural Language Processing determine which previous words most strongly influence next predictions |
| Beam Search Probability | Maintains multiple high-probability generation paths simultaneously, enabling Natural Language Processing to explore alternatives before committing to final output |
| Perplexity Measurement | Quantifies how surprised Natural Language Processing is by actual text, serving as a metric for model quality and confidence in probability assignments |
4. Natural Language Processing and Context Without Comprehension
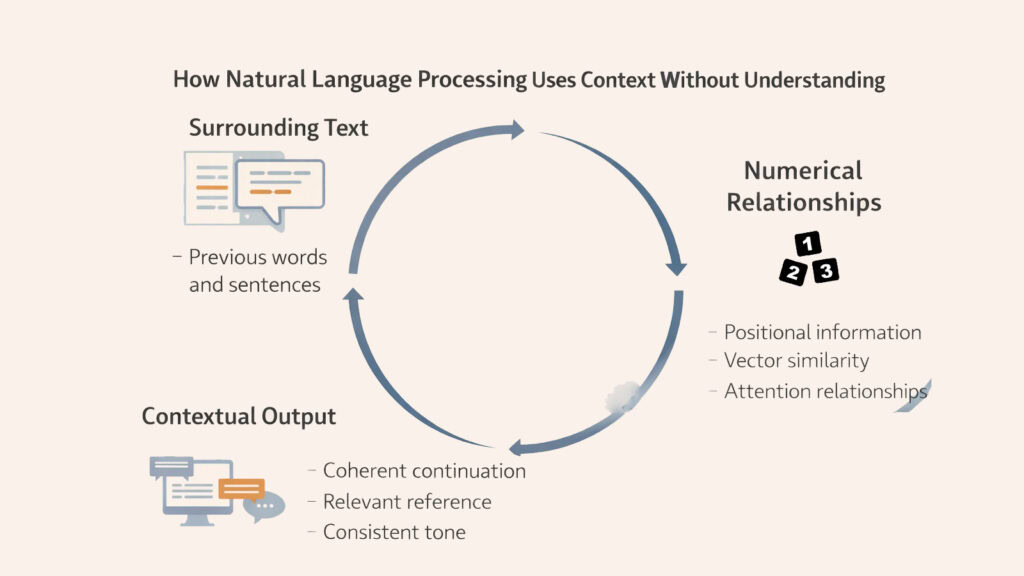
Human readers use context intuitively, drawing on everything from sentence structure to world knowledge to interpret meaning. Natural Language Processing handles context through mathematical relationships between tokens, creating numerical representations that capture positional and semantic proximity. This allows systems to maintain coherence across long passages without ever experiencing understanding.
The mechanism works through attention, a technique that lets Natural Language Processing weigh the relevance of earlier words when processing later ones. When the system encounters a pronoun like “it,” attention mechanisms identify which previous noun the pronoun likely references by calculating numerical similarity scores. The machine never knows what “it” means, but it can link tokens based on learned patterns of reference.
Context windows determine how much previous text Natural Language Processing can consider simultaneously. Early systems could only look back a few words, limiting their ability to maintain coherence. Modern models process thousands of tokens at once, enabling them to track themes, maintain consistent perspectives, and reference information from much earlier in a document. This expanded capacity creates the impression of sustained comprehension.
The numerical nature of context representation means Natural Language Processing can track relationships that would overwhelm human working memory. A system can simultaneously consider hundreds of potential connections between words, weighting each by learned importance. This computational advantage allows for consistency across long texts even without a genuine understanding of what those texts discuss.
Context handling in Natural Language Processing demonstrates both remarkable capability and fundamental limitations. Systems can maintain topical coherence, track multiple entities across paragraphs, and generate contextually appropriate responses. Yet they do so through pattern matching and statistical association rather than the interpretive understanding humans bring to reading. The difference matters when edge cases or novel situations arise that fall outside learned patterns.
NLP Context Management Techniques
| Context Mechanism | Function in NLP Text Understanding |
|---|---|
| Self-Attention | Allows each word to weigh relationships with all other words in a sequence, enabling Natural Language Processing to capture long-range dependencies through numerical similarity |
| Positional Encoding | Injects information about word order into token representations, helping Natural Language Processing maintain awareness of sequence structure in its contextual calculations |
| Hierarchical Context | Processes text at multiple scales from words to sentences to documents, allowing Natural Language Processing to track themes and topics across different organizational levels |
| Memory Networks | Store and retrieve relevant information from earlier text, enabling Natural Language Processing to reference specific facts or details when generating contextually appropriate responses |
| Context Windows | Define the span of previous text Natural Language Processing can access, with larger windows enabling better coherence but requiring more computational resources |
| Cross-Attention | Links representations between different text sequences, allowing Natural Language Processing to align information across languages in translation or between questions and passages in comprehension |
5. Natural Language Processing and Learning From Massive Text Exposure
Unlike human language learners who receive explicit instruction in grammar and vocabulary, Natural Language Processing improves through sheer exposure to text. Systems train on billions of words drawn from books, websites, articles, and conversations. This massive dataset allows them to encounter nearly every common pattern, phrase, and construction multiple times. Repetition replaces reasoning as the path to capability.
The scale of training data distinguishes modern Natural Language Processing from earlier approaches. A system might process the equivalent of thousands of books in a single training session, encountering the same grammatical structures and semantic patterns repeatedly across diverse contexts. This exposure builds robust statistical models that generalize across new situations by recognizing familiar patterns in unfamiliar combinations.
Training does not teach Natural Language Processing what language means or why humans use it. Instead, the process adjusts billions of numerical parameters to minimize prediction errors. When the system incorrectly predicts the next word in a training sentence, internal values shift slightly to make the correct prediction more likely in the future. Repeated across countless examples, these small adjustments accumulate into sophisticated language models.
The dependency on massive datasets creates both power and vulnerability. More training data generally produces better performance, explaining why leading Natural Language Processing systems require enormous computational resources. However, this approach also means the system absorbs whatever patterns exist in its training data, including biases, errors, and outdated information. Natural Language Processing has no mechanism for filtering truth from falsehood or fair from biased.
Learning through exposure rather than explicit instruction explains why Natural Language Processing can handle language nuances that would be difficult to encode as rules. Idioms, contextual meanings, and subtle grammatical variations emerge naturally from observing how language actually gets used. The system need not understand why certain expressions work. It simply learns that they appear frequently in its training corpus and reproduces them in appropriate contexts.
NLP Training Data Characteristics
| Data Aspect | Impact on NLP System Development |
|---|---|
| Corpus Scale | Larger training sets expose Natural Language Processing to more patterns and variations, improving performance but requiring substantial computational resources for processing |
| Domain Diversity | Varied text sources help Natural Language Processing generalize across contexts, while narrow datasets produce systems that excel in specific areas but struggle elsewhere |
| Data Quality | Clean, accurate training text improves Natural Language Processing reliability, while errors and inconsistencies in source material propagate into model predictions |
| Temporal Coverage | Recent training data helps Natural Language Processing reflect current language use, though systems cannot update knowledge without complete retraining on new text |
| Language Balance | Representation of multiple languages and dialects affects whether Natural Language Processing performs equitably across linguistic communities or favors dominant languages |
| Bias Patterns | Social and cultural biases present in training text become embedded in Natural Language Processing behavior, requiring careful curation to mitigate problematic outputs |
6. Natural Language Processing and the Appearance of Understanding
The remarkable fluency of modern Natural Language Processing creates a powerful illusion. When a system answers questions accurately, maintains conversational flow, and generates coherent paragraphs, users naturally attribute understanding to it. This perception reflects deep human intuitions that equate language mastery with intelligence. Yet the appearance emerges entirely from the mechanisms described in earlier sections, none of which involve comprehension.
Fluency arises from pattern recognition applied at scale. NLP generates grammatically correct, contextually appropriate text because it has observed millions of similar examples. The system selects words that typically appear in similar contexts, maintains structures that commonly occur together, and avoids combinations rarely seen in training data. This produces output that feels natural to human readers, even though no understanding guides its creation.
Speed amplifies the illusion. NLP responds nearly instantaneously, creating the impression of effortless comprehension. Humans associate quick responses with intelligence and understanding, making it difficult to remember that rapid statistical calculation differs fundamentally from actual thinking. The machine’s speed reflects computational power, not insight.
Relevance completes the illusion. Natural Language Processing generates responses that address queries appropriately because pattern recognition extends to identifying which training examples resemble the current input. When you ask a question, the system activates patterns associated with similar questions in its training data, producing answers that mirror how humans responded to those earlier queries. This relevance feels like understanding, but represents sophisticated pattern matching.
The gap between appearance and reality matters when NLP encounters situations that diverge from training patterns. Systems confidently generate plausible-sounding nonsense when faced with questions that combine familiar elements in novel ways. They cannot recognize their own limitations because they lack the metacognitive awareness that understanding would provide. This explains why Natural Language Processing can simultaneously seem remarkably intelligent and strangely oblivious.
NLP Capabilities That Simulate Understanding
| Apparent Capability | How NLP Achieves the Effect Without Comprehension |
|---|---|
| Conversational Coherence | Maintains dialogue flow by tracking recent exchanges and generating contextually appropriate responses based on patterns from training conversations |
| Question Answering | Identifies relevant information by pattern matching between queries and training text, producing answers that mirror human responses to similar questions |
| Text Summarization | Extracts and recombines high-salience phrases from source material, creating condensed versions that preserve key information through statistical importance scoring |
| Sentiment Analysis | Classifies emotional tone by recognizing word patterns associated with positive or negative expressions in training data, without experiencing emotion |
| Language Translation | Maps source text to target language by learning parallel patterns across bilingual datasets, producing translations through statistical correspondence not meaning transfer |
| Text Generation | Creates original content by selecting high-probability word sequences that maintain grammatical and thematic consistency with preceding context |
Conclusion: Natural Language Processing and Why Reading Without Understanding Still Works
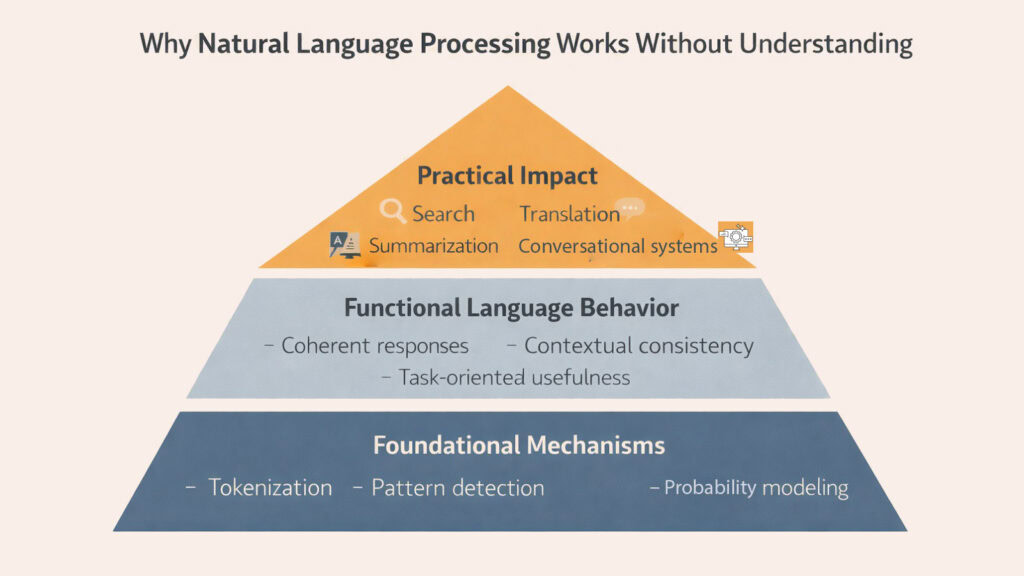
The paradox at the heart of Natural Language Processing deserves recognition rather than dismissal. Systems that cannot understand language nonetheless process it with remarkable effectiveness. This capability emerges from the six mechanisms explored throughout this article, each contributing a piece to the larger illusion of comprehension. Tokenization breaks language into processable units. Pattern recognition identifies recurring structures. Probability calculations guide prediction. Context tracking maintains coherence. Massive exposure refines statistical models. Together, these create fluent responses that feel intelligent without requiring intelligence.
The design reflects a profound shift in how machines interact with human language. Earlier approaches attempted to encode meaning explicitly through rules and logical structures. Modern Natural Language Processing abandons this goal entirely, focusing instead on statistical patterns that emerge from vast data. This pivot toward pattern over meaning enables systems to handle language’s complexity and ambiguity in ways rule-based approaches never could.
Understanding why Natural Language Processing works without comprehension clarifies both its strengths and boundaries. These systems excel at tasks that benefit from pattern recognition across large datasets. They struggle when situations demand genuine reasoning, common sense, or awareness of real-world constraints absent from training text. Recognizing this distinction helps users deploy Natural Language Processing appropriately while avoiding overreliance on systems that simulate understanding without possessing it.
The effectiveness of reading without comprehension suggests that human-like understanding may not be necessary for many language tasks. Natural Language Processing reshapes the relationship between humans and machines by creating functional communication channels that operate on fundamentally different principles than human cognition. This development marks not a step toward artificial minds but rather the creation of powerful tools that complement human capabilities in novel ways.
As Natural Language Processing continues evolving, the six mechanisms described here will likely grow more sophisticated. Yet the fundamental approach will probably remain: machines that read through patterns, not meaning. This architectural choice reflects practical engineering rather than philosophical limitation. For numerous applications, statistical pattern recognition provides exactly what users need from language technology. The illusion of understanding matters less than the reality of usefulness.
NLP Practical Applications and Limitations
| Application Domain | How NLP Functions and Where It Reaches Boundaries |
|---|---|
| Search Engines | Matches queries to documents through keyword and semantic similarity, excelling at information retrieval but sometimes missing user intent when novel or ambiguous |
| Virtual Assistants | Processes voice commands and generates responses using dialogue patterns from training data, handling routine requests well but struggling with complex or unusual queries |
| Content Moderation | Identifies problematic text by recognizing patterns associated with harmful content, achieving scale but sometimes flagging edge cases inappropriately |
| Machine Translation | Converts between languages using parallel text patterns, producing fluent translations for common content but faltering with cultural nuance or technical terminology |
| Writing Assistance | Suggests improvements and completes text based on stylistic patterns, helping with grammar and flow but lacking judgment about content accuracy or appropriateness |
| Information Extraction | Identifies entities and relationships in documents through pattern recognition, efficiently processing large volumes but occasionally misinterpreting ambiguous references |
Read More Tech Articles
- Quantum Computer Anatomy: 8 Powerful Components Inside
- Quantum Computing: 6 Powerful Concepts Driving Innovation
- 8 Powerful Smart Devices To Brighten Your Life
- 8 E-Readers: Epic Characters in a Library Adventure
- Smart TV Brands: 8 Epic Directors for Screen Magic
- Laptop Brands as Celebrities: Meet 8 Alluring Stars
- 8 Best AI Image Generators That You Must Know About
- AI Images: 8 Simple Steps To Create Images Using AI


