
Table of Contents
Introduction to Data Infrastructure in Modern Technology
Every enterprise today runs on data. But the ability to collect, store, process, and use that data depends on the systems and architectures operating behind the scenes. That invisible foundation is Data Infrastructure, and it has become one of the most important pillars of modern technology. Organizations no longer view data as a simple byproduct of operations. They treat it as a strategic asset. Cloud platforms require scalable storage systems. Artificial intelligence and machine learning models depend on clean, structured datasets. Analytics platforms need fast and reliable database architectures. All these capabilities rely on a data infrastructure that can manage growing volumes, multiple formats, and real-time demands efficiently.
Modern enterprise environments now generate data from customer transactions, IoT devices, mobile applications, cloud services, APIs, and internal systems simultaneously. Managing this scale requires infrastructure that is distributed, resilient, scalable, and capable of supporting future workloads alongside current operations. What separates modern Data Infrastructure from older approaches is its interconnected nature. Storage systems link with databases. ETL pipelines feed analytics platforms. Integration frameworks connect cloud services with on-premises systems. Governance and observability tools oversee the ecosystem for compliance, security, and reliability. None of these components operates independently. Together, they create a unified data ecosystem.
Current trends influencing the data infrastructure domain encompass cloud-native architectures, AI-driven systems, edge computing, real-time analytics, and multi-cloud environments. Organizations are increasingly implementing lakehouse models, event-driven systems, and data mesh frameworks to enhance scalability and decentralize ownership. This article examines eight significant systems that characterize contemporary Data Infrastructure, detailing their functionality, importance, and their role in supporting the wider enterprise technology ecosystem.
Table 1: Data Infrastructure Overview — Eight Core Systems
| System | Role in Data Infrastructure |
| Data Storage Systems | Stores structured, semi-structured, and unstructured data across cloud and on-premises environments |
| Database Architecture | Organizes and retrieves data efficiently using relational, NoSQL, and distributed database models |
| Data Pipelines and ETL | Automates data collection, transformation, and delivery across enterprise systems |
| Data Integration Systems | Connects applications, APIs, SaaS platforms, and cloud services to eliminate data silos |
| Data Governance and Compliance | Enforces security policies, access controls, and regulatory compliance across data assets |
| Big Data Processing | Handles large-scale data workloads using distributed computing and parallel processing frameworks |
| Real-Time Data Infrastructure | Enables low-latency event processing, stream analytics, and instant operational intelligence |
| Data Observability and Reliability | Monitors pipeline health, detects anomalies, and ensures data quality and system uptime |
1. Data Infrastructure and Modern Data Storage Systems
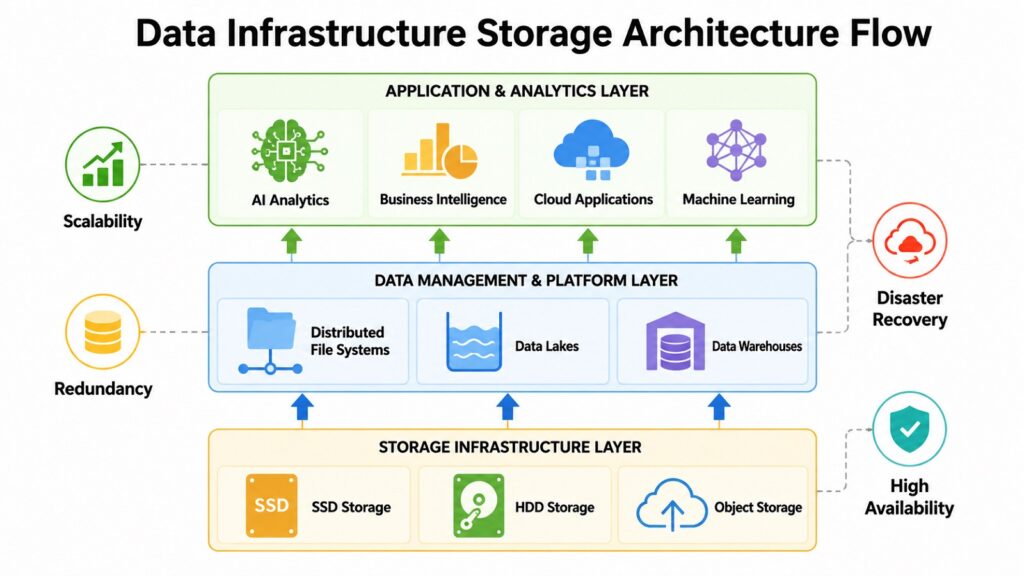
Storage is where everything begins. Before an organization can analyze data, train a model, or generate a report, it needs a place to keep that data — one that is fast, reliable, and scalable. Data Infrastructure starts with storage, and the evolution of storage systems over the past decade has been remarkable.
Traditional storage architectures relied on centralized systems that worked well for smaller datasets. As data volumes grew — driven by mobile applications, social platforms, cloud services, and connected devices — those systems began to buckle. Enterprises needed distributed architectures that could spread storage across many nodes, scale horizontally, and remain available even when individual components failed.
Today, most modern organizations rely on a combination of cloud object storage, distributed file systems, and purpose-built data platforms. Amazon S3 and Azure Blob Storage are widely used for storing unstructured data such as logs, images, video, and raw datasets. Google Cloud Storage serves similar purposes within the Google Cloud ecosystem. For large-scale analytical workloads, platforms like Snowflake and Databricks offer managed storage combined with processing capabilities. Hadoop HDFS, while less dominant than it once was, still powers many on-premises big data environments.
The choice between a data lake and a data warehouse reflects a fundamental design decision. Data lakes store raw data in its native format, making them flexible but harder to query efficiently. Data warehouses store structured, cleaned data optimized for analytics, but they require more upfront processing. The lakehouse architecture, adopted by platforms like Databricks and Snowflake, attempts to combine both approaches — providing the flexibility of a data lake with the performance of a warehouse.
Modern storage systems must also support AI and machine learning workloads, which require fast access to large datasets during training. SSD-based storage, high-bandwidth access layers, and intelligent tiering systems help optimize performance for these use cases. Redundancy mechanisms and disaster recovery configurations ensure that critical data remains available even during infrastructure failures.
As hybrid cloud environments become more common, storage systems need to span multiple clouds and on-premises locations while maintaining consistent access controls and governance. The future of storage within Data Infrastructure lies in intelligent, adaptive systems that can automatically tier data based on access frequency, cost, and performance requirements.
Table 2: Data Infrastructure Storage Systems — Types and Characteristics
| Storage Type | Characteristics and Use Cases |
| Amazon S3 Object Storage | Stores unstructured data at massive scale; used for backups, media, logs, and ML datasets |
| Azure Blob Storage | Cloud object storage integrated with Azure services; supports tiered access and lifecycle policies |
| Hadoop HDFS | Distributed file system for on-premises big data workloads; fault-tolerant block-based storage |
| Snowflake Data Warehouse | Managed cloud warehouse with separation of storage and compute; supports multi-cloud deployment |
| Databricks Lakehouse | Combines data lake flexibility with warehouse performance on Delta Lake format |
| Google Cloud Storage | Scalable object storage with global availability; integrates with BigQuery and Vertex AI |
| SSD-Based Storage Layers | Used for low-latency access in transactional and AI workloads; reduces I/O bottlenecks |
| Hybrid Cloud Storage | Spans on-premises and cloud environments; enables consistent governance and data movement |
2. Data Infrastructure and Scalable Database Architecture
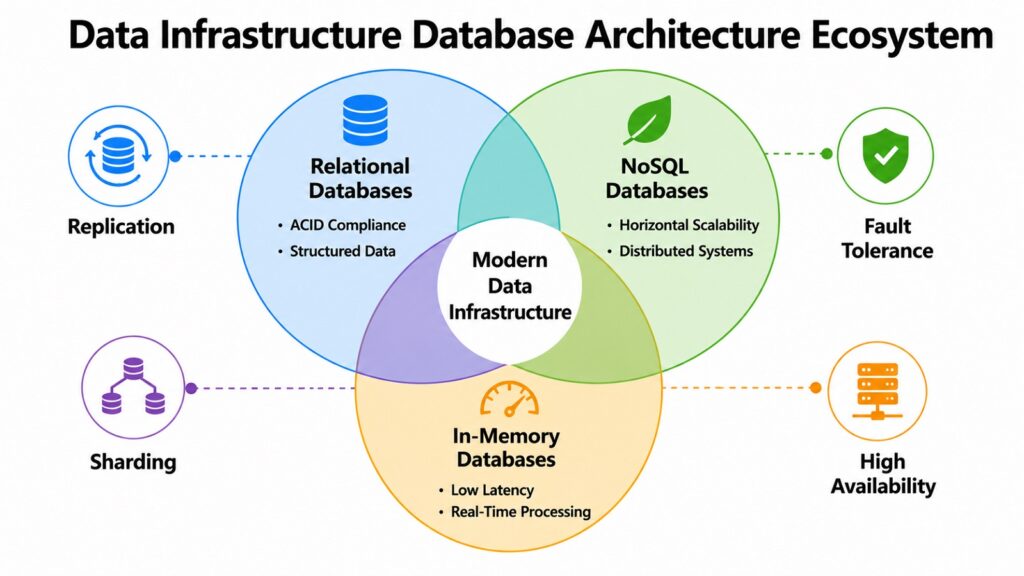
Databases are the structured heart of Data Infrastructure. They organize data in ways that make it retrievable, consistent, and queryable at scale. As enterprise systems grew more complex, the limitations of traditional relational databases became clear, pushing organizations toward distributed and cloud-native alternatives.
Relational databases like PostgreSQL and MySQL remain widely used for transactional systems, content management platforms, and applications that require structured data and ACID compliance. ACID stands for Atomicity, Consistency, Isolation, and Durability — the four properties that guarantee reliable transactions. These databases work well when data structure is well-defined and consistency is non-negotiable.
NoSQL databases emerged to handle scenarios where flexibility and scale matter more than strict consistency. MongoDB supports document-based storage for applications with dynamic schemas. Cassandra is designed for write-heavy, distributed workloads where high availability is more important than immediate consistency. Redis operates as an in-memory database, making it ideal for caching, session management, and real-time leaderboards where sub-millisecond response times are required.
The CAP theorem — which states that a distributed database can only guarantee two of three properties: Consistency, Availability, and Partition Tolerance — is central to understanding database design tradeoffs. Different systems make different choices. CockroachDB prioritizes consistency and availability with horizontal scalability. Google Spanner achieves globally distributed transactions with strong consistency, which was considered impossible for many years before its introduction.
Graph databases like Neo4j handle data with complex relationships — such as social networks, fraud detection graphs, and recommendation systems — far more efficiently than traditional relational models. In-memory databases serve latency-sensitive applications where disk-based retrieval would be too slow.
Modern database architecture connects directly with AI systems and cloud-native applications. Machine learning models often require low-latency reads from feature stores. SaaS platforms demand databases that scale automatically without manual intervention. Distributed databases support multi-region deployments that keep data close to users around the world.
Looking ahead, autonomous databases powered by AI-driven optimization are gaining traction. These systems can automatically tune indexes, adjust resource allocation, and recommend schema changes based on query patterns. As data volumes and application complexity grow, intelligent database architecture will become even more central to resilient Data Infrastructure.
Table 3: Data Infrastructure Database Systems — Comparison of Types
| Database Type | Key Characteristics and Common Technologies |
| Relational (SQL) | Structured schemas, ACID compliance; used in transactional systems — PostgreSQL, MySQL |
| Document NoSQL | Flexible JSON-like documents; useful for dynamic schemas — MongoDB, CouchDB |
| Wide-Column NoSQL | Optimized for large-scale distributed writes; used in IoT and analytics — Cassandra, HBase |
| In-Memory Database | Sub-millisecond response times; ideal for caching and real-time systems — Redis, Memcached |
| Distributed SQL | Horizontal scaling with strong consistency; used in cloud-native apps — CockroachDB, Spanner |
| Graph Database | Models complex relationships; used in fraud detection and recommendations — Neo4j, Amazon Neptune |
| Time-Series Database | Optimized for sequential time-stamped data; used in IoT and monitoring — InfluxDB, TimescaleDB |
| Autonomous Database | AI-driven self-tuning and self-healing; reduces manual administration — Oracle Autonomous DB |
3. Data Infrastructure and Efficient Data Pipelines and ETL Systems
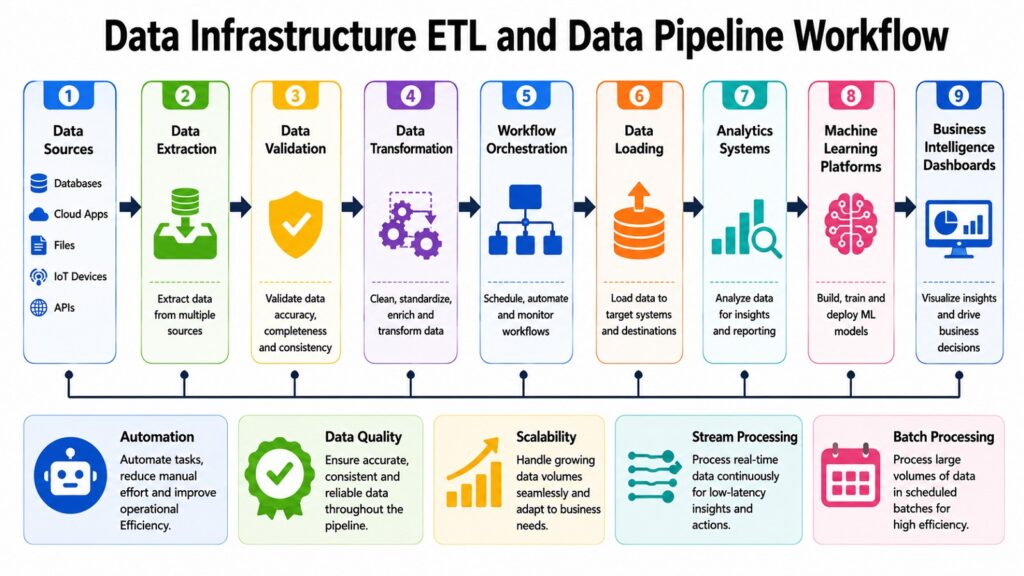
No matter how strong the storage and database layers are, data does not move, transform, or reach the right systems on its own. That is the role of data pipelines and ETL systems — the operational backbone that keeps Data Infrastructure working as a living, breathing ecosystem.
ETL stands for Extract, Transform, Load. In a traditional ETL process, data is extracted from source systems, transformed into the right format through a series of cleaning and validation steps, and then loaded into a target system such as a data warehouse. ELT, the modern variant, loads raw data first and performs transformation within the target system — which works better when the destination has strong processing capabilities, as cloud warehouses often do.
The challenge that drives the need for automated pipelines is the sheer fragmentation of enterprise data. A typical organization pulls data from CRM platforms, marketing tools, financial systems, customer portals, IoT sensors, and cloud services. Each source uses different formats, schemas, and update frequencies. Bringing all of that together reliably, on schedule, and with consistent quality requires well-designed pipeline architecture.
Technologies like Apache Airflow enable complex workflow orchestration, allowing teams to define, schedule, and monitor pipeline jobs using code. Apache NiFi handles data ingestion from diverse sources with built-in flow-based programming. Informatica and Talend are enterprise-grade ETL platforms that offer visual workflow design, data quality monitoring, and integration with major cloud services. AWS Glue provides a serverless ETL service within the Amazon ecosystem. dbt, or data build tool, focuses specifically on data transformation within the warehouse layer, making it popular among analytics engineers.
Batch processing handles large volumes of data at scheduled intervals, which works well for daily reports and periodic data loads. Stream processing handles data as it arrives in real time, which is essential for fraud detection, live dashboards, and event-driven applications. Modern pipelines often combine both approaches, using a lambda architecture or kappa architecture depending on the use case.
Serverless pipeline architectures reduce infrastructure management overhead by automatically scaling compute resources based on workload demand. Event-driven workflows trigger pipeline execution based on data arrival rather than time schedules, reducing latency and improving responsiveness. AI-assisted data engineering tools are beginning to automate schema detection, anomaly flagging, and pipeline optimization — reducing the manual effort required to maintain complex data workflows.
Table 4: Data Infrastructure Pipeline Systems — Tools and Capabilities
| Tool or Approach | Role in Data Infrastructure Pipelines |
| Apache Airflow | Workflow orchestration platform for scheduling and monitoring complex data pipelines |
| Apache NiFi | Ingests and routes data from diverse sources with visual flow-based programming |
| dbt (Data Build Tool) | Handles SQL-based data transformation and testing within the warehouse layer |
| AWS Glue | Serverless ETL service for ingestion, transformation, and cataloging within AWS environments |
| Informatica | Enterprise ETL and data quality platform supporting cloud, hybrid, and on-premises pipelines |
| Talend | Open-source ETL platform with strong connectors for SaaS, cloud, and database systems |
| ETL vs ELT | ETL transforms before loading (traditional); ELT loads first and transforms inside the warehouse (modern) |
| Batch vs Stream Processing | Batch handles scheduled data loads; stream processes events in real time as they arrive |
4. Data Infrastructure and Enterprise Data Integration Systems
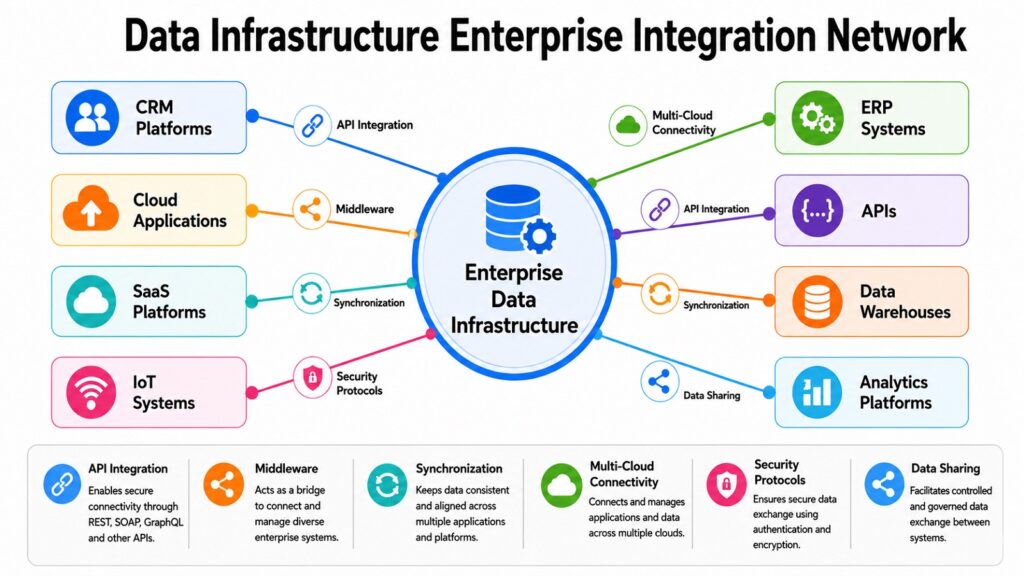
Modern enterprises rarely operate from a single system. They run dozens or hundreds of applications — CRM tools, ERP platforms, cloud databases, marketing analytics systems, financial software, and third-party APIs. Each of these generates data. Without integration, that data stays trapped inside isolated silos, invisible to the rest of the organization.
Data integration systems solve this problem by creating connections between applications, databases, and cloud services within modern Data Infrastructure. These systems ensure that data flows reliably between source and destination, that transformations happen correctly, and that business processes remain synchronized across platforms.
API integration is one of the most fundamental approaches. Modern SaaS applications expose APIs that allow external systems to read and write data programmatically. Integration platforms like MuleSoft act as middleware that sits between systems, managing API connections, data translations, and security policies at scale. MuleSoft is widely used in large enterprises for connecting heterogeneous application landscapes.
Apache Kafka is a distributed event streaming platform that has become central to real-time data integration. It decouples data producers from consumers, allowing systems to publish and subscribe to event streams without tight coupling. Fivetran automates data ingestion from SaaS sources into data warehouses, handling connector maintenance and schema changes automatically. Boomi and Microsoft Power Platform offer low-code integration capabilities that allow non-technical teams to build integrations without writing custom code.
Master data management, or MDM, addresses the challenge of data consistency across systems. When the same customer, product, or location appears in multiple systems with slightly different representations, MDM ensures that all systems work from a single, authoritative definition. Enterprise service buses, or ESBs, provide a centralized message routing layer that coordinates communication between services — though microservices architectures have partially replaced ESBs in modern infrastructure.
Integration systems face real challenges. Latency can accumulate when data must pass through multiple transformation and routing layers. Synchronization conflicts occur when two systems update the same data simultaneously. Security concerns arise when sensitive data travels across network boundaries. Multi-cloud complexity grows when systems span AWS, Azure, and Google Cloud simultaneously.
The future points toward API-first architectures and real-time connected ecosystems where every system shares data continuously rather than in scheduled batches. Cloud-native integration platforms are replacing legacy middleware with lighter, more scalable approaches that fit naturally within modern Data Infrastructure.
Table 5: Data Infrastructure Integration Tools — Roles and Capabilities
| Integration Tool | Role in Enterprise Data Infrastructure |
| MuleSoft Anypoint | Enterprise integration platform connecting APIs, apps, and data at scale with governance controls |
| Apache Kafka | Distributed event streaming for real-time integration between producers and consumers |
| Fivetran | Automated data ingestion from SaaS sources into cloud warehouses with schema change handling |
| Boomi | Low-code iPaaS platform for cloud, on-premises, and hybrid integration workflows |
| Microsoft Power Platform | Connects Microsoft and third-party apps with low-code flows for business automation |
| Master Data Management | Ensures consistent, authoritative definitions for shared entities like customers and products |
| Enterprise Service Bus | Centralized message routing layer for inter-service communication in legacy architectures |
| API-First Integration | Builds integration around reusable APIs to enable modular, scalable data connectivity |
5. Data Infrastructure and Strong Data Governance and Compliance
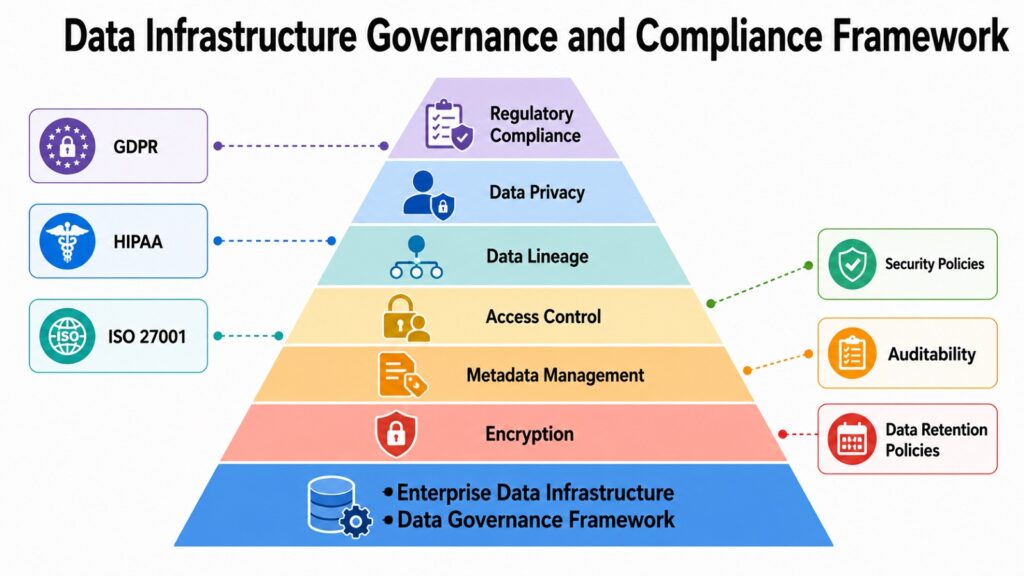
Data has value only when it can be trusted. When data is inconsistent, poorly documented, or accessed without proper controls, it becomes a liability rather than an asset. Data governance gives organizations the frameworks they need to treat data as a managed, reliable, and accountable resource within their Data Infrastructure.
The regulatory landscape has made governance more urgent than ever. GDPR, the General Data Protection Regulation enacted by the European Union, imposes strict requirements on how organizations collect, store, and process personal data. HIPAA governs health information in the United States with specific rules around access, encryption, and breach notification. ISO 27001 provides a globally recognized framework for information security management. Organizations operating across borders must navigate multiple regulatory frameworks simultaneously, which creates significant compliance complexity.
At a technical level, governance encompasses several interconnected capabilities. Metadata management creates catalogs that describe what data exists, where it lives, and how it is structured. Data lineage tracks how data moves and transforms across systems, giving analysts confidence that a number in a report reflects what they think it reflects. Access control systems enforce role-based permissions that determine who can read, write, or modify specific datasets. Encryption protects data at rest and in transit. Auditing logs every access event so organizations can investigate unauthorized activity.
Technologies like Collibra and Alation provide enterprise data catalog and governance platforms that help teams discover, document, and govern data assets at scale. Apache Atlas offers open-source metadata management for Hadoop-based environments. Microsoft Purview integrates with the Azure ecosystem to provide unified governance across cloud and on-premises data sources.
Real-world governance challenges go beyond technology. Shadow data — datasets created and maintained outside official systems — represents a significant risk because it often lacks controls and documentation. Insider threats remain one of the most common sources of data breaches. Cross-border data management requires organizations to understand where data is stored physically, since some regulations restrict data from leaving specific jurisdictions.
AI governance is an emerging area within this space. As organizations deploy machine learning models that make consequential decisions, they need frameworks that ensure those models are trained on appropriate data, free from bias, and subject to audit. Modern governance platforms are beginning to incorporate AI-specific controls alongside traditional data policies, expanding the scope of Data Infrastructure governance considerably.
Table 6: Data Infrastructure Governance — Frameworks and Technologies
| Governance Element | Role in Data Infrastructure Compliance and Trust |
| GDPR Compliance | Governs collection and processing of EU personal data; requires consent, rights management, and breach notification |
| HIPAA Compliance | Regulates health data in the US with rules on access controls, encryption, and audit trails |
| ISO 27001 | International standard for information security management systems and risk control frameworks |
| Collibra | Enterprise data governance platform for cataloging, lineage tracking, and policy enforcement |
| Apache Atlas | Open-source metadata and lineage management for Hadoop and cloud data ecosystems |
| Microsoft Purview | Unified governance for Azure cloud and on-premises data with automated data discovery |
| Data Lineage Tracking | Documents how data flows and transforms across systems to ensure accuracy and traceability |
| AI Governance Frameworks | Monitors ML models for bias, auditability, and compliance with evolving AI regulations |
6. Data Infrastructure and High-Performance Big Data Processing
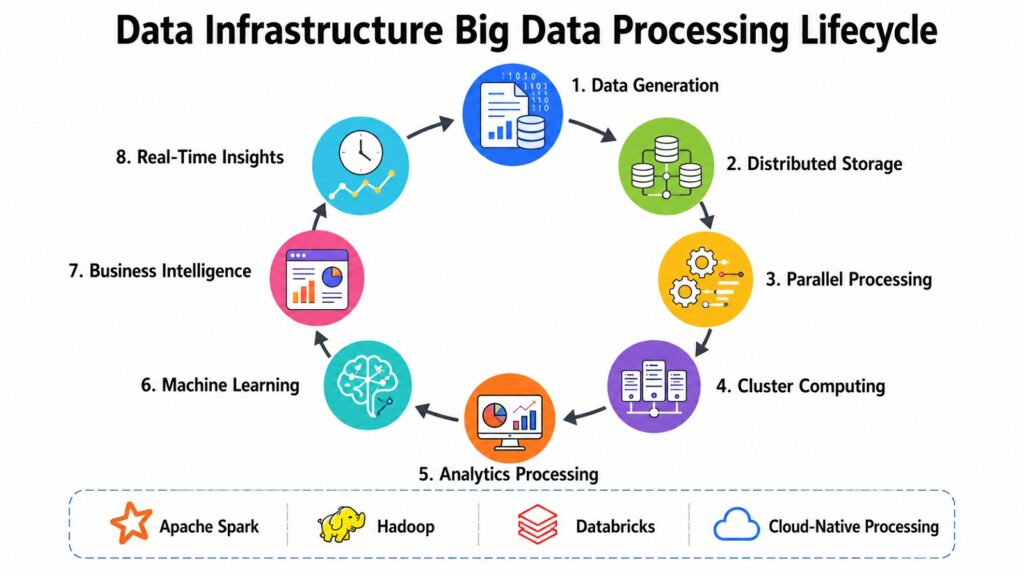
Some data problems are too large for any single machine to solve. The datasets generated by financial markets, social media platforms, IoT sensor networks, and genomics research routinely reach scales of terabytes and petabytes. Processing that data quickly and reliably requires a fundamentally different approach — one built on distributed computing and parallel processing.
Big data processing systems distribute computational workloads across clusters of machines, allowing each node to process a portion of the dataset simultaneously. The results are then aggregated to produce the final output. This approach, formalized in Google’s MapReduce programming model, made large-scale data processing practical for the first time. Hadoop brought that model to open-source environments, combining HDFS storage with MapReduce processing in a framework that thousands of organizations adopted.
Apache Spark improved significantly on Hadoop’s batch-oriented MapReduce model by introducing in-memory processing, which dramatically reduces the latency of iterative workloads. Spark supports batch processing, stream processing, SQL queries, machine learning, and graph processing through a unified API. Databricks, built on top of Spark, adds a managed cloud environment, collaborative notebooks, and enterprise-grade reliability. Apache Flink provides low-latency stream processing with strong stateful computation capabilities, making it popular for real-time analytics and event-driven applications. Google BigQuery offers a serverless, cloud-native data warehouse with powerful analytical processing that scales automatically.
Big data processing connects directly with machine learning pipelines. Training a large model requires iterating over massive datasets many times, which demands fast, distributed data access. Recommendation systems at companies like Amazon and Netflix process enormous interaction logs to generate personalized suggestions in near real time. Fraud detection systems at banks analyze millions of transactions per second to identify anomalous patterns before damage occurs.
Implementation challenges are real. Infrastructure costs for large clusters can be substantial. Latency optimization requires careful partitioning, caching, and resource allocation strategies. Data skew — where some nodes receive disproportionately more data than others — can bottleneck distributed jobs. Managing these systems requires experienced engineering teams and continuous performance monitoring.
The shift toward cloud-native big data systems has reduced some of this complexity. Serverless processing architectures allow organizations to run large analytical jobs without managing underlying infrastructure. AI-driven analytics platforms are beginning to optimize query execution automatically, choosing the best processing strategies based on data volume, schema, and query patterns.
Table 7: Data Infrastructure Big Data Processing — Platforms and Capabilities
| Processing Platform | Key Capabilities and Enterprise Use Cases |
| Apache Spark | In-memory distributed processing for batch, streaming, ML, and SQL workloads at scale |
| Hadoop MapReduce | Batch processing framework for large-scale on-premises data workloads using distributed clusters |
| Databricks | Managed cloud platform built on Spark with collaborative notebooks and enterprise reliability |
| Apache Flink | Low-latency stateful stream processing for real-time analytics and event-driven applications |
| Google BigQuery | Serverless cloud data warehouse with automatic scaling and petabyte-scale SQL analytics |
| Batch vs Stream Processing | Batch handles large scheduled jobs; stream processing handles real-time, continuous data flows |
| Distributed Computing | Spreads workloads across many nodes in a cluster to achieve parallelism and fault tolerance |
| AI-Driven Analytics | Uses machine learning to automate query optimization, resource allocation, and insight discovery |
7. Data Infrastructure and Real-Time Data Processing Systems
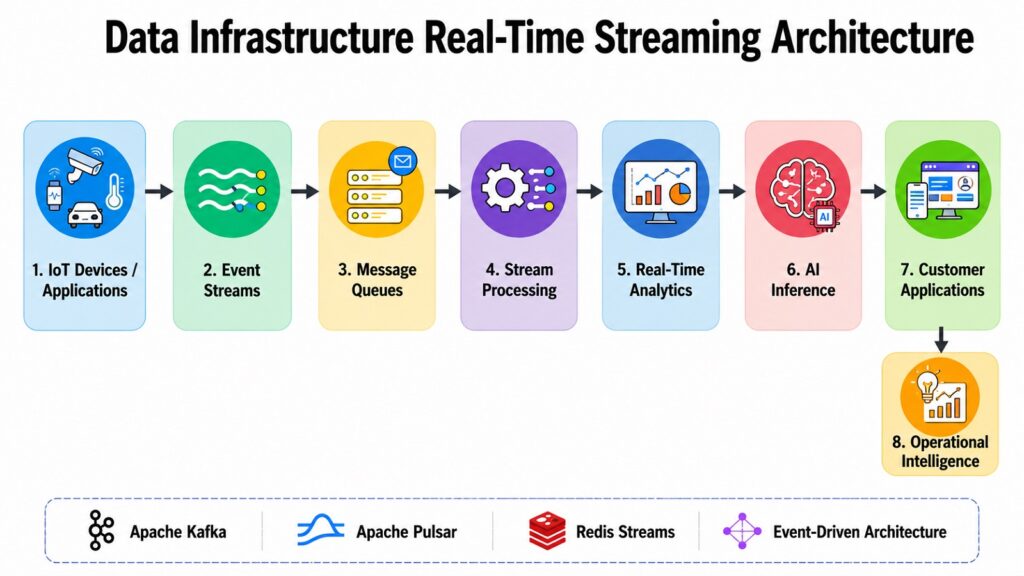
The expectation that data should be available, accurate, and actionable within milliseconds has become a baseline requirement across modern industries. Real-time processing systems are what make that expectation possible within modern Data Infrastructure, enabling everything from fraud alerts to live product recommendations.
At the core of real-time architecture is the concept of event-driven processing. Instead of waiting for data to accumulate and be processed in batches, event-driven systems react to each data event as it arrives. A customer placing an order, a sensor recording a temperature reading, or a user clicking a product — each of these events can trigger downstream processing immediately.
Apache Kafka has emerged as the prevailing standard for constructing real-time data pipelines. It functions as a distributed message queue that separates event producers from consumers, enabling the publication and consumption of thousands of events per second with minimal latency. Apache Pulsar provides comparable functionalities with enhanced multi-tenancy support and tiered storage. RabbitMQ serves as a lightweight message broker ideal for task queues and application-level messaging. Redis Streams facilitates lightweight stream processing within the Redis ecosystem. Amazon Kinesis delivers a managed streaming service on the AWS platform.
Real-time systems are transforming industries in concrete ways. Financial institutions use streaming platforms to detect fraudulent transactions within seconds of occurrence — before funds are transferred. E-commerce platforms generate personalized recommendations in real time based on a user’s browsing and purchase behavior. Ride-sharing applications track driver and passenger locations continuously to optimize matching algorithms. Streaming platforms like Netflix monitor playback quality in real time and adjust bitrates automatically. Supply chain platforms track inventory and shipment events as they happen.
Building reliable real-time systems is genuinely difficult. Throughput optimization requires careful partition management and consumer group configuration. Fault tolerance demands replication and offset management to ensure no events are lost if a consumer fails. Infrastructure monitoring must cover latency, message lag, consumer health, and partition leadership continuously. Scaling stream processing workloads often requires dynamic resource allocation and careful state management.
Edge computing is extending real-time processing closer to the data source. Instead of sending all IoT sensor data to a central cloud for processing, edge nodes perform initial filtering, aggregation, and anomaly detection locally — reducing latency and bandwidth costs. AI-powered streaming systems are beginning to run inference models directly on stream data, enabling real-time decision-making without round trips to central processing infrastructure.
Table 8: Data Infrastructure Real-Time Systems — Tools and Applications
| Technology or Concept | Role in Real-Time Data Infrastructure |
| Apache Kafka | Distributed event streaming platform; core of real-time pipelines across industries |
| Apache Pulsar | Multi-tenant streaming with tiered storage; suited for cloud-native deployments |
| RabbitMQ | Lightweight message broker for task queues and application-level event communication |
| Amazon Kinesis | Managed real-time data streaming service within the AWS ecosystem |
| Redis Streams | Lightweight stream processing for low-latency event workflows within Redis environments |
| Edge Computing | Processes data near the source to reduce latency and bandwidth in IoT environments |
| Event-Driven Architecture | Triggers processing based on data events rather than schedules, reducing latency significantly |
| Batch vs Real-Time Processing | Batch processes data in scheduled intervals; real-time processes events as they occur |
8. Data Infrastructure and Modern Data Observability and Reliability
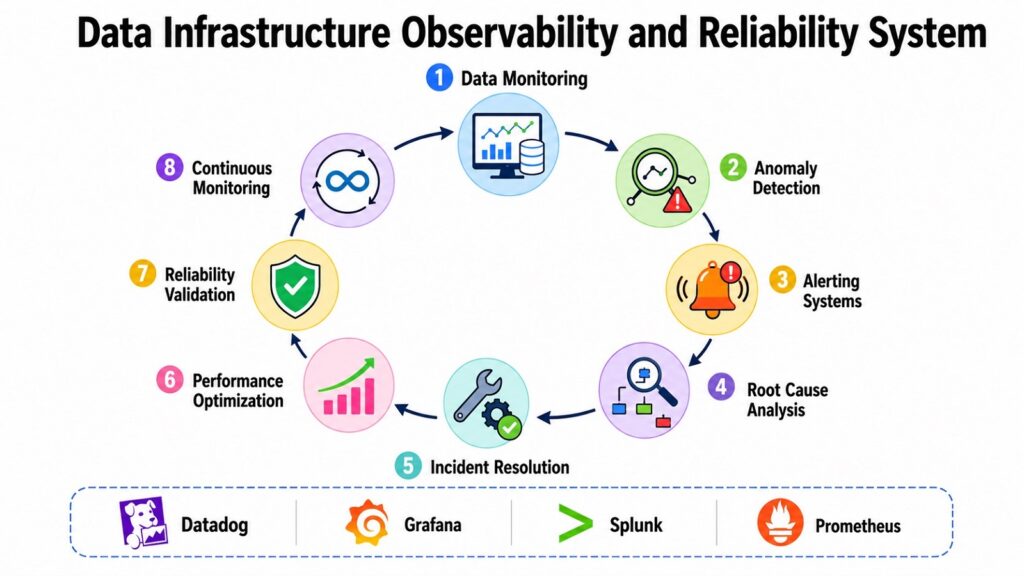
A Data Infrastructure can be architecturally sophisticated and still fail the organization if nobody knows when something goes wrong. Pipelines break. Data arrives late. Schemas change unexpectedly. Tables silently fill with nulls. Without observability, these problems propagate quietly through analytics systems until someone notices that a report is wrong — often after a business decision has already been made based on bad data.
Observability in the context of Data Infrastructure means having the tools, processes, and visibility needed to understand the health of data systems at any given moment. It covers monitoring pipeline execution, tracking data quality metrics, detecting anomalies, measuring system latency, and enabling rapid root-cause analysis when something breaks.
Datadog is a widely adopted platform for infrastructure and application monitoring, offering dashboards, alerting, and log management across cloud environments. Grafana provides open-source visualization for metrics collected from systems like Prometheus, which is a time-series monitoring tool favored in Kubernetes environments. Splunk ingests and analyzes machine-generated log data at scale, making it useful for security monitoring and operational intelligence. Monte Carlo focuses specifically on data observability — monitoring tables, pipelines, and transformations for freshness, volume, distribution, and schema anomalies. OpenTelemetry provides a vendor-neutral framework for collecting traces, metrics, and logs from distributed systems.
Data quality monitoring is a specific dimension of observability that checks whether data meets defined standards — correct formats, expected value ranges, referential integrity, and completeness. When quality checks fail, alerting systems notify the responsible teams so they can investigate before downstream consumers are affected.
The challenges of operating observability systems at scale are real. Alert fatigue is common when monitoring systems generate too many notifications, many of which turn out to be false positives. Engineers begin to ignore alerts, which defeats the purpose entirely. Multi-cloud environments create visibility gaps because each cloud provider uses different monitoring tools and log formats. Infrastructure blind spots can exist where no monitoring coverage has been established, leaving entire segments of the data ecosystem unobserved.
AI-powered monitoring systems are addressing some of these challenges by automatically distinguishing genuine anomalies from normal variation. Autonomous observability platforms can correlate events across multiple systems to identify root causes faster than human analysts. Predictive infrastructure analytics can detect early warning signals of pipeline degradation before it results in failure. These capabilities are becoming essential components of resilient, enterprise-grade Data Infrastructure.
Table 9: Data Infrastructure Observability Tools — Capabilities and Use Cases
| Tool or Concept | Role in Data Infrastructure Reliability |
| Datadog | Full-stack monitoring platform for infrastructure, pipelines, and applications across cloud environments |
| Grafana | Open-source visualization tool for metrics and logs collected from Prometheus and other sources |
| Prometheus | Time-series monitoring system for cloud-native and Kubernetes-based infrastructure environments |
| Splunk | Log analytics and SIEM platform for security monitoring and operational intelligence at scale |
| Monte Carlo | Data observability platform monitoring table freshness, volume, schema, and distribution anomalies |
| OpenTelemetry | Vendor-neutral framework for collecting distributed traces, metrics, and logs across systems |
| SLA Monitoring | Tracks service level agreements to ensure pipeline execution and data delivery meet defined standards |
| AI-Powered Monitoring | Uses machine learning to detect anomalies, reduce alert fatigue, and predict infrastructure failures |
Conclusion on Data Infrastructure and the Future of Modern Data Systems
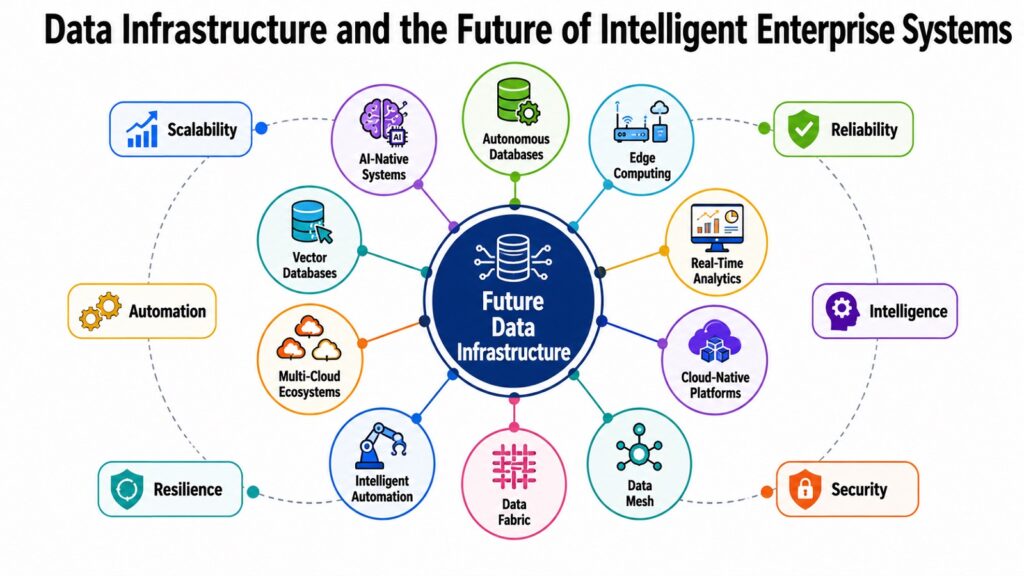
The eight systems explored in this article do not operate independently. They form an interconnected ecosystem where storage supports databases, databases power pipelines, pipelines integrate systems, governance enforces control, big data platforms analyze large volumes, and observability tools maintain reliability. This interconnection is what makes Data Infrastructure a core pillar of modern technology. Organizations with strong Data Infrastructure gain a major advantage. Their analytics are faster and more reliable. Their AI models perform better. Their applications deliver real-time experiences. Their compliance processes are stronger, and engineering teams spend less time resolving system failures because the infrastructure is built for resilience.
The industry is also evolving rapidly. AI-native infrastructure is embedding machine learning directly into storage, processing, and monitoring systems. Autonomous platforms are improving optimization and recovery processes. Real-time analytics are replacing traditional batch reporting. Data mesh frameworks are decentralizing ownership across teams, while edge computing is reducing latency by processing data closer to the source. At the same time, multi-cloud strategies are becoming standard, requiring infrastructure that works seamlessly across providers.
Despite these innovations, the fundamentals still matter. Advanced monitoring cannot compensate for weak storage architecture, and real-time streaming systems are ineffective if databases cannot deliver low-latency performance. Strong engineering foundations remain essential. For organizations building or modernizing their Data Infrastructure, the opportunity is substantial. Scalable, governed, integrated, and observable systems create long-term value as data volumes and business demands continue to grow. Investing in intelligent Data Infrastructure is no longer only a technology decision. It is a strategic decision that shapes competitiveness, decision-making speed, and long-term growth in a data-driven economy.
Table 10: Data Infrastructure Future Trends — Technologies and Directions
| Trend | Impact on Future Data Infrastructure |
| AI-Native Infrastructure | Embeds ML capabilities into storage, processing, and monitoring systems for autonomous optimization |
| Data Mesh Architecture | Decentralizes data ownership to domain teams, reducing bottlenecks and improving accountability |
| Edge Computing | Processes data near the source to reduce latency in IoT, mobile, and industrial environments |
| Real-Time Analytics | Replaces batch reporting with continuous, low-latency intelligence for operational decision-making |
| Multi-Cloud Strategy | Distributes workloads across AWS, Azure, and GCP to improve resilience and avoid vendor lock-in |
| Autonomous Data Systems | Self-healing and self-optimizing pipelines that reduce manual engineering intervention |
| Cloud-Native Ecosystems | Fully managed, containerized data services that scale on demand without infrastructure management |
| Intelligent Compliance Monitoring | Automates regulatory compliance tracking across jurisdictions using AI-driven governance tools |


